The number of comparisons made to match the pattern P=0001 and T=000010001010001
are shown as follows:
Step 1:
|
Position(i) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
Text T |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
Position(j) |
0 |
1 |
2 |
3 |
|
Pattern P |
0 |
0 |
0 |
1 |
Here, the positions on which comparisons are made are: (0,0), (1,1), (2,2), (3,3).
Step 2:
|
Position(i) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
Text T |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
Position(j) |
0 |
1 |
2 |
3 |
|
Pattern P |
0 |
0 |
0 |
1 |
Here, there is a shift of one position to the right so, the positions on which the comparisons are made are: (1,0), (2,1), (3,2), (4,3).
Step 3:
|
Position(i) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
Text T |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
Position(j) |
0 |
1 |
2 |
3 |
|
Pattern P |
0 |
0 |
0 |
1 |
Here, there is a shift of two positions to the right so, the positions on which the comparisons are made are: (2,0), (3,1), (4,2).
Step 4:
|
Position(i) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
Text T |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
Position(j) |
0 |
1 |
2 |
3 |
|
Pattern P |
0 |
0 |
0 |
1 |
There is a shift of three positions to the right, so the positions on which the comparison is done are: (3,0), (4,1).
Step 5:
|
Position(i) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
Text T |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
Position(j) |
0 |
1 |
2 |
3 |
|
Pattern P |
0 |
0 |
0 |
1 |
There is a shift of four positions to the right, so the positions on which the comparison stops is: (4,0).
Step 6:
|
Position(i) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
Text T |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
Position(j) |
0 |
1 |
2 |
3 |
|
Pattern P |
0 |
0 |
0 |
1 |
The shift occurs five positions to the right, so the comparisons are done at the positions: (5,0), (6,1), (7,2), (8,3).
Step 7:
|
Position(i) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
Text T |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
Position(j) |
0 |
1 |
2 |
3 |
|
Pattern P |
0 |
0 |
0 |
1 |
The shift occurs six positions to the right, so the comparisons are done at the position: (6,0), (7,1), (8,2).
Step 8:
|
Position(i) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
Text T |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
Position(j) |
0 |
1 |
2 |
3 |
|
Pattern P |
0 |
0 |
0 |
1 |
On shifting seven positions to the right, the comparisons are made at the positions: (7,0), (8,1).
Step 9:
|
Position(i) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
Text T |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
Position(j) |
0 |
1 |
2 |
3 |
|
Pattern P |
0 |
0 |
0 |
1 |
The shifting is done eight positions to the right, the comparisons are made at the positions: (8,0).
|
Position(i) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
Text T |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
Position(j) |
0 |
1 |
2 |
3 |
|
Pattern P |
0 |
0 |
0 |
1 |
The shifting is done nine positions to the right, comparisons are made at the positions: (9,0), (10,1).
Step 11:
|
Position(i) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
Text T |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
Position(j) |
0 |
1 |
2 |
3 |
|
Pattern P |
0 |
0 |
0 |
1 |
The shifting is done ten positions to the right, therefore the comparisons are done at the position: (10,0).
Step 12:
|
Position(i) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
Text T |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
|
Position(j) |
0 |
1 |
2 |
3 |
|
Pattern P |
0 |
0 |
0 |
1 |
The shifting is done eleven positions to the right, so the comparisons are done at the positions; (11,0), (12,1), (13,2), (14,3).
Thus, it can be concluded that the entire pattern P matches the text T in the Step 2, so the number of comparisons are 8 ( 4 comparisons from Step 1 and 4 comparisons from Step 2). The pattern P also matches the text T in the Step 6 but in that case the number of comparisons will be more, that is, 18.
NAIVE-STRING MATCHER algorithm is used to find a pattern in a
text. But this algorithm runs in 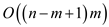 time.
NAIVE-STRING MATCHER can be accelerated so that it runs in
time.
NAIVE-STRING MATCHER can be accelerated so that it runs in
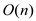 ,
if the patter P contains different characters and text
contains n characters.
,
if the patter P contains different characters and text
contains n characters.
An algorithm to accelerate NAIVE-STRING MATCHER for pattern P that has different characters is given in the below step:
NAIVE-STRING MATCHER (T, P)
//copy the length of Text into variable n.
1. n= T. length
// copy the length of pattern into variable m.
2. m=P. length
// initialize the value of i and s with 0. Variable s is used to traverse the text whereas i //is used to traverse the pattern.
3. Initialize i and s with 0.
//while loop is used to check the value of s
4. while s
//compare the value of i with m
5. if i==m
//pattern match
6. print “ pattern occurs with sift” s
7. reset the value of i to 0
// compare the value of pattern with text
8. if P [i] == T[s]
//increment the value of i and s
9. i=i+1 and s=s+1
10. else
//if the value i is 0
11. if i ==0
//increment the value of s by 1
12. s=s+1
13. reset the value of i to 0
Explanation of the Algorithm:
• During matching if, p[i] mismatch at T[s] then the next matching will start from s+1 index of T[] rather than start from i+1 index.
• In line 1 and 2 of the above algorithm copy the length of text T and pattern P into variable n and m.
• In line 3rd initialize the value of variable i and s.
• The while loop of line 4-13 checks the matches of the pattern.
• In line 5-6, it compares the value of variable i with the length of pattern m until all positions match successfully.
• In line 8 compare each value of text T with pattern P. if pattern P and text T match then increment the value of variable i and s by 1.
• In line 10-13, if the value of i will be 0 then increments the value of shift s by 1.
The above algorithm used only one while loop to match the
pattern P from text T so
the time complexity of algorithm will be 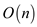 .
.
Since, P is the pattern having length m and T is the text
having length n. The d -ary alphabet is given by: 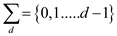 , where
d
, where
d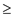 2.
2.
Let the string be s, the probability that the first i-1
characters will match can deduce the probability that the 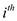 character
will be looked at, while doing the string comparison, which is
character
will be looked at, while doing the string comparison, which is
 .
So, the expected number of steps obtained by the linearity of
expression is given by the following algorithm:
.
So, the expected number of steps obtained by the linearity of
expression is given by the following algorithm:
DISTINCT-NAÏVE-STRING (T, P)
1 n=T.length
2 m=P.length
3 k=0
4 for s=0 to n-m do
5 j=1
6 if P [1…m] ==T [s+1…. s+m] then…… (line 4 of naïve algorithm)
7 k=s
8 j=0
9 while T[k+j]==P[j] and j
10 if j==m then
11 print “Pattern occurs with the shift”, k
12 end if
13 end while
14 end if
15 s=s+j
16 end for
The expected number of character to character comparisons is given by:

Hence, it can be proved that the expected number of character to character comparisons made by the implicit loop in line 4 of the naïve algorithm is:
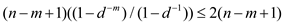
A polynomial time algorithm to determine whether a pattern P
with gap characters exists in the given text T can be deduced by
partitioning the pattern P into substrings 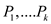 which are
filled with gap characters. To find the pattern P in the text T
search for
which are
filled with gap characters. To find the pattern P in the text T
search for  and then
continue searching for
and then
continue searching for 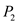 and so
on.
and so
on.
Thus, the pattern P is decomposed into the form  where _
denotes the gap. If the length of the pattern P is m and length of
text T is n, then the run time of the algorithm is
where _
denotes the gap. If the length of the pattern P is m and length of
text T is n, then the run time of the algorithm is  .
.
The algorithm for determining if pattern P occurs in the text T is as follows:
1. Let P= 
2. S=T
3. For i=1,2…. K do
4. Find the leftmost occurrence  of
of  in S; if
does not appear in S
in S; if
does not appear in S
5. Halt, report “P does not gap-appear in T”
6. If  is the left
position of in
is the left
position of in

7. Let R be the suffix of S starting at t+1;
8. S=R
9. End for
10. Report “P gap appears in T”